
6.基于Zookeeper环境搭建Hadoop高可用集群
基于zookeeeper搭建Hadoop高可用集群
一、高可用简介
Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解:
1.1 高可用整体架构
HDFS 高可用架构如下:

HDFS 高可用架构主要由以下组件所构成:
- Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
- 主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
- Zookeeper 集群:为主备切换控制器提供主备选举支持。
- 共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。主 NameNode 和 NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
- DataNode 节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
1.2 基于 QJM 的共享存储系统的数据同步机制分析
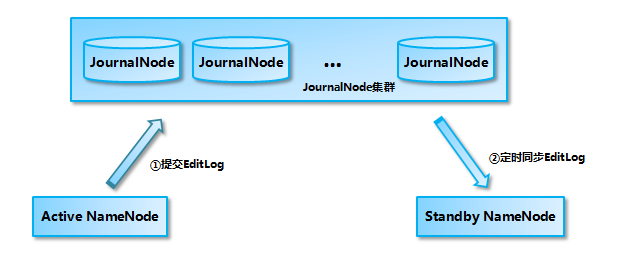
目前 Hadoop 支持使用 Quorum Journal Manager (QJM) 或 Network File System (NFS) 作为共享的存储系统,这里以 QJM 集群为例进行说明:Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog,当 Active NameNode 宕机后, Standby NameNode 在确认元数据完全同步之后就可以对外提供服务。
需要说明的是向 JournalNode 集群写入 EditLog 是遵循 “过半写入则成功” 的策略,所以你至少要有 3 个 JournalNode 节点,当然你也可以继续增加节点数量,但是应该保证节点总数是奇数。同时如果有 2N+1 台 JournalNode,那么根据过半写的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。
1.3 NameNode 主备切换
NameNode 实现主备切换的流程下图所示:
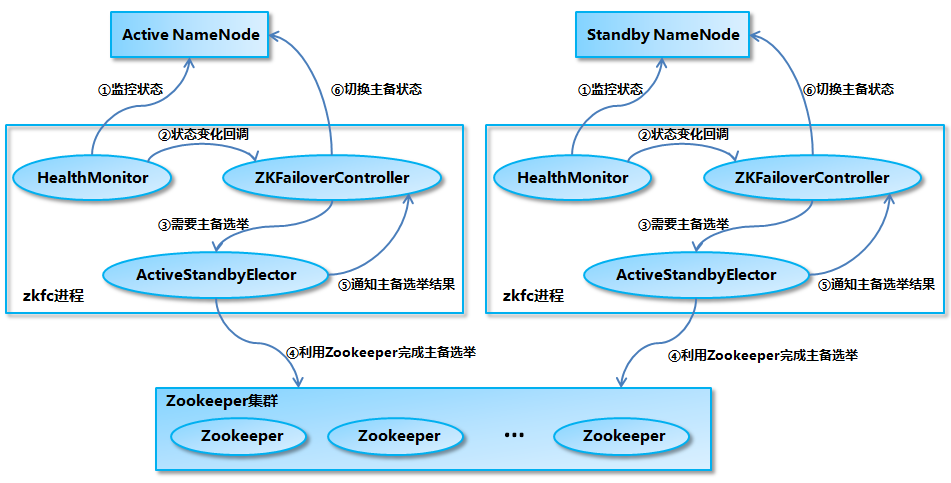
\1. HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。
- HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
- 如果 ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector 来进行自动的主备选举。
- ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。
- ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的 NameNode 成为主 NameNode 或备 NameNode。
- ZKFailoverController 调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
1.3.1 自动触发主备选举
NameNode 在选举成功后,会在 zk 上创建了一个 /hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点,而没有选举成功的备 NameNode 会监控这个节点,通过 Watcher 来监听这个节点的状态变化事件,ZKFC 的 ActiveStandbyElector 主要关注这个节点的 NodeDeleted 事件(这部分实现跟 Kafka 中 Controller 的选举一样)。
如果 Active NameNode 对应的 HealthMonitor 检测到 NameNode 的状态异常时, ZKFailoverController 会主动删除当前在 Zookeeper 上建立的临时节点 /hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock,这样处于 Standby 状态的 NameNode 的 ActiveStandbyElector 注册的监听器就会收到这个节点的 NodeDeleted 事件。收到这个事件之后,会马上再次进入到创建 /hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点的流程,如果创建成功,这个本来处于 Standby 状态的 NameNode 就选举为主 NameNode 并随后开始切换为 Active 状态。
当然,如果是 Active 状态的 NameNode 所在的机器整个宕掉的话,那么根据 Zookeeper 的临时节点特性,/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点会自动被删除,从而也会自动进行一次主备切换。
1.3.2 HDFS 脑裂问题
在实际中,NameNode 可能会出现这种情况,NameNode 在垃圾回收(GC)时,可能会在长时间内整个系统无响应,因此,也就无法向 zk 写入心跳信息,这样的话可能会导致临时节点掉线,备 NameNode 会切换到 Active 状态,这种情况,可能会导致整个集群会有同时有两个 NameNode,这就是脑裂问题。
脑裂问题的解决方案是隔离(Fencing),主要是在以下三处采用隔离措施:
第三方共享存储:任一时刻,只有一个 NN 可以写入; DataNode:需要保证只有一个 NN 发出与管理数据副本有关的删除命令; Client:需要保证同一时刻只有一个 NN 能够对 Client 的请求发出正确的响应。 关于这个问题目前解决方案的实现如下:
ActiveStandbyElector 为了实现 fencing,会在成功创建 Zookeeper 节点 hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 从而成为 Active NameNode 之后,创建另外一个路径为 /hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 的持久节点,这个节点里面保存了这个 Active NameNode 的地址信息; Active NameNode 的 ActiveStandbyElector 在正常的状态下关闭 Zookeeper Session 的时候,会一起删除这个持久节点; 但如果 ActiveStandbyElector 在异常的状态下 Zookeeper Session 关闭 (比如前述的 Zookeeper 假死),那么由于 /hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 是持久节点,会一直保留下来,后面当另一个 NameNode 选主成功之后,会注意到上一个 Active NameNode 遗留下来的这个节点,从而会回调 ZKFailoverController 的方法对旧的 Active NameNode 进行 fencing。 在进行 fencing 的时候,会执行以下的操作:
首先尝试调用这个旧 Active NameNode 的 HAServiceProtocol RPC 接口的 transitionToStandby 方法,看能不能把它转换为 Standby 状态; 如果 transitionToStandby 方法调用失败,那么就执行 Hadoop 配置文件之中预定义的隔离措施。 Hadoop 目前主要提供两种隔离措施,通常会选择第一种:
sshfence:通过 SSH 登录到目标机器上,执行命令 fuser 将对应的进程杀死; shellfence:执行一个用户自定义的 shell 脚本来将对应的进程隔离。 只有在成功地执行完成 fencing 之后,选主成功的 ActiveStandbyElector 才会回调 ZKFailoverController 的 becomeActive 方法将对应的 NameNode 转换为 Active 状态,开始对外提供服务。
NameNode 选举的实现机制与 Kafka 的 Controller 类似,那么 Kafka 是如何避免脑裂问题的呢?
Controller 给 Broker 发送的请求中,都会携带 controller epoch 信息,如果 broker 发现当前请求的 epoch 小于缓存中的值,那么就证明这是来自旧 Controller 的请求,就会决绝这个请求,正常情况下是没什么问题的; 但是异常情况下呢?如果 Broker 先收到异常 Controller 的请求进行处理呢?现在看 Kafka 在这一部分并没有适合的方案; 正常情况下,Kafka 新的 Controller 选举出来之后,Controller 会向全局所有 broker 发送一个 metadata 请求,这样全局所有 Broker 都可以知道当前最新的 controller epoch,但是并不能保证可以完全避免上面这个问题,还是有出现这个问题的几率的,只不过非常小,而且即使出现了由于 Kafka 的高可靠架构,影响也非常有限,至少从目前看,这个问题并不是严重的问题。
1.4 YARN高可用
YARN ResourceManager 的高可用与 HDFS NameNode 的高可用类似,但是 ResourceManager 不像 NameNode ,没有那么多的元数据信息需要维护,所以它的状态信息可以直接写到 Zookeeper 上,并依赖 Zookeeper 来进行主备选举。
二、集群规划
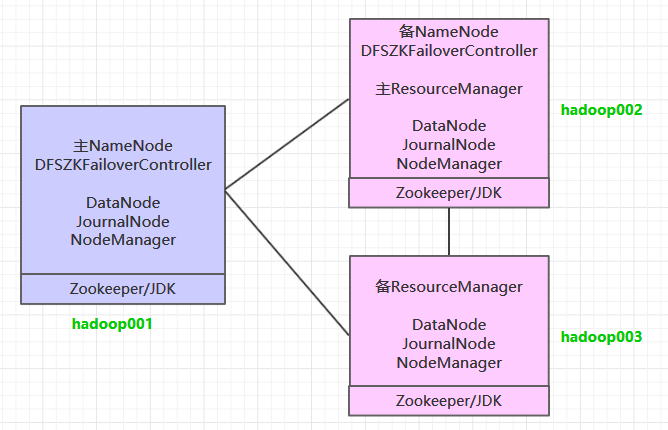
按照高可用的设计目标:需要保证至少有两个 NameNode (一主一备) 和 两个 ResourceManager (一主一备) ,同时为满足“过半写入则成功”的原则,需要至少要有 3 个 JournalNode 节点。这里使用三台主机进行搭建,集群规划如下:
三、前置条件
- 所有服务器都安装有 JDK,安装步骤可以参见:Linux 下 JDK 的安装;
- 搭建好 ZooKeeper 集群,搭建步骤可以参见:Zookeeper 单机环境和集群环境搭建
- 所有服务器之间都配置好 SSH 免密登录。
四、集群配置
4.1 下载并解压
下载 Hadoop。这里我下载的是 CDH 版本 Hadoop,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
1 | # tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz |
4.2 配置环境变量
编辑 profile 文件:
1 | # vim /etc/profile |
增加如下配置:
1 | export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2 |
执行 source 命令,使得配置立即生效:
1 | # source /etc/profile |
4.3 修改配置
进入 ${HADOOP_HOME}/etc/hadoop 目录下,修改配置文件。各个配置文件内容如下:
1. hadoop-env.sh
1 | # 指定JDK的安装位置 |
2. core-site.xml
1 | <configuration> |
3. hdfs-site.xml
1 | <configuration> |
4. yarn-site.xml
1 | <configuration> |
5. mapred-site.xml
1 | <configuration> |
5. slaves
配置所有从属节点的主机名或 IP 地址,每行一个。所有从属节点上的 DataNode 服务和 NodeManager 服务都会被启动。
1 | hadoop001 |
4.4 分发程序
将 Hadoop 安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下 Hadoop 的环境变量。
1 | # 将安装包分发到hadoop002 |
五、启动集群
5.1 启动ZooKeeper
分别到三台服务器上启动 ZooKeeper 服务:
1 | zkServer.sh start |
5.2 启动Journalnode
分别到三台服务器的的 ${HADOOP_HOME}/sbin 目录下,启动 journalnode 进程:
1 | hadoop-daemon.sh start journalnode |
5.3 初始化NameNode
在 hadop001 上执行 NameNode 初始化命令:
1 | hdfs namenode -format |
执行初始化命令后,需要将 NameNode 元数据目录的内容,复制到其他未格式化的 NameNode 上。元数据存储目录就是我们在 hdfs-site.xml 中使用 dfs.namenode.name.dir 属性指定的目录。这里我们需要将其复制到 hadoop002 上:
1 | scp -r /home/hadoop/namenode/data hadoop002:/home/hadoop/namenode/ |
5.4 初始化HA状态
在任意一台 NameNode 上使用以下命令来初始化 ZooKeeper 中的 HA 状态:
1 | hdfs zkfc -formatZK |
5.5 启动HDFS
进入到 hadoop001 的 ${HADOOP_HOME}/sbin 目录下,启动 HDFS。此时 hadoop001 和 hadoop002 上的 NameNode 服务,和三台服务器上的 DataNode 服务都会被启动:
1 | start-dfs.sh |
5.6 启动YARN
进入到 hadoop002 的 ${HADOOP_HOME}/sbin 目录下,启动 YARN。此时 hadoop002 上的 ResourceManager 服务,和三台服务器上的 NodeManager 服务都会被启动:
1 | start-yarn.sh |
需要注意的是,这个时候 hadoop003 上的 ResourceManager 服务通常是没有启动的,需要手动启动:
1 | yarn-daemon.sh start resourcemanager |
六、查看集群
6.1 查看进程
成功启动后,每台服务器上的进程应该如下:
1 | [root@hadoop001 sbin]# jps |
6.2 查看Web UI
HDFS 和 YARN 的端口号分别为 50070 和 8080,界面应该如下:
此时 hadoop001 上的 NameNode 处于可用状态:
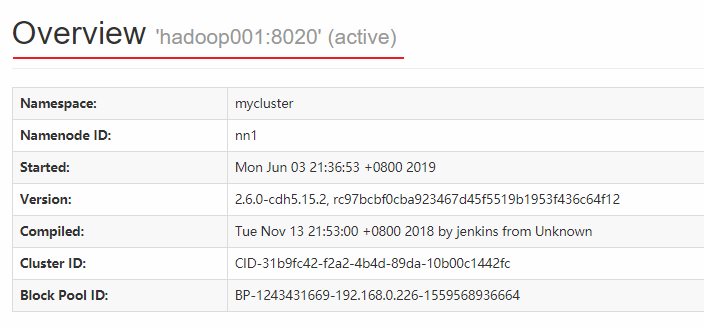
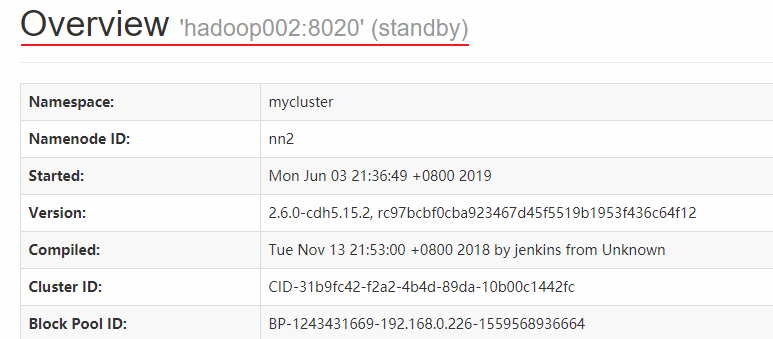
而 hadoop002 上的 NameNode 则处于备用状态:
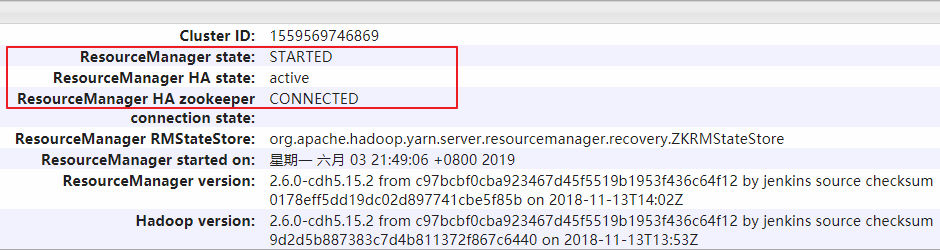
hadoop002 上的 ResourceManager 处于可用状态:
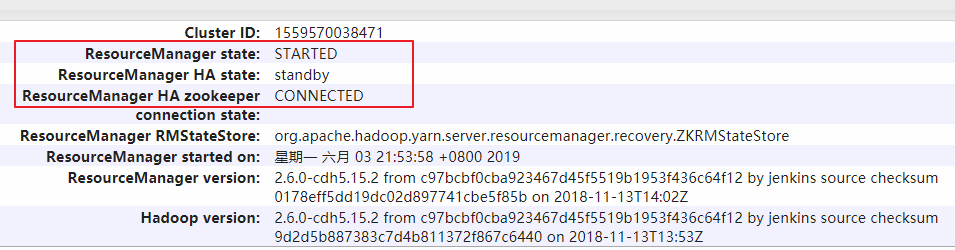
hadoop003 上的 ResourceManager 则处于备用状态:
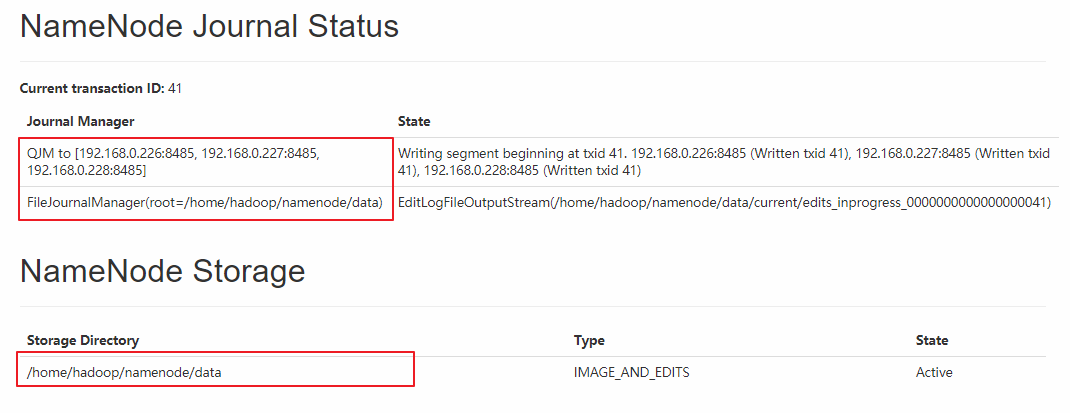
同时界面上也有 Journal Manager 的相关信息:
## 七、集群的二次启动
上面的集群初次启动涉及到一些必要初始化操作,所以过程略显繁琐。但是集群一旦搭建好后,想要再次启用它是比较方便的,步骤如下(首选需要确保 ZooKeeper 集群已经启动):
在 hadoop001 启动 HDFS,此时会启动所有与 HDFS 高可用相关的服务,包括 NameNode,DataNode 和 JournalNode:
1 | start-dfs.sh |
在 hadoop002 启动 YARN:
1 | start-yarn.sh |
这个时候 hadoop003 上的 ResourceManager 服务通常还是没有启动的,需要手动启动:
1 | yarn-daemon.sh start resourcemanager |
参考资料
以上搭建步骤主要参考自官方文档:




