
1.什么是爬虫?
1.什么是爬虫?
不知道各位是否遇到过这样的需求, 就是我们总是希望能够保存互联网上的一些重要的数据信息为己所用。比如:
- 在浏览到一些优秀的图片时,总想保存起来留为日后做桌面上的壁纸
- 在浏览到一些重要的数据时(各行各业),希望保留下来日后为自己进行各种销售行为增光添彩
- 在浏览到一些好看的视频时, 希望保存在硬盘里供日后使用
- 在浏览到一些十分优秀的歌声曲目时, 希望保存下来供我们在烦闷的生活中增添一份精彩
那么恭喜你,本教程将十分的适合于你。因为爬虫就是通过编写程序来爬取互联网上的优秀资源(图片, 音频, 视频, 数据)
2.爬虫和Python
爬虫一定要用Python么? 非也~ 用Java也行, C也可以. 请各位记住,编程语言只是工具. 抓到数据是你的目的. 用什么工具去达到你的目的都是可以的. 和吃饭一样, 可以用叉子也可以用筷子, 最终的结果都是你能吃到饭. 那为什么大多数人喜欢用Python呢? 答案: 因为Python写爬虫简单. 不理解? 问: 为什么吃米饭不用刀叉? 用筷子? 因为简单! 好用!
而Python是众多编程语言中, 小白上手最快, 语法最简单。更重要的是,这货有非常多的关于爬虫能用到的第三方支持库。说直白点儿,就是你用筷子吃饭, 我还附送你一个佣人。帮你吃! 这样吃的是不是更爽了!更容易了~
3.爬虫合法么?
首先, 爬虫在法律上是不被禁止的,也就是说法律是允许爬虫存在的,但是, 爬虫也具有违法的. 就像菜刀一样, 法律是允许菜刀的存在的, 但是你要是用来砍人,那对不起, 没人惯着你。就像王欣说过的,技术是无罪的。主要看你用它来干嘛, 比方说有些人就利用爬虫+一些黑客技术每秒钟对着bilibili爬上十万八千次,那这个肯定是不被允许的。
爬虫分为善意的爬虫和恶意的爬虫
善意的爬虫, 不破坏被爬取的网站的资源(正常访问, 一般频率不高, 不窃取用户隐私)
恶意的爬虫, 影响网站的正常运营(抢票, 秒杀, 疯狂solo网站资源造成网站宕机
综上, 为了避免进🍊,我们还是要安分守己。时常优化自己的爬虫程序避免干扰到网站的正常运行。并且在使用爬取到的数据时,发现涉及到用户隐私和商业机密等敏感内容时, 一定要及时终止爬取和传播
4.爬虫的矛与盾
反爬机制:网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略:爬虫程序可以通过制定相关的策略或者技术手段,破解 户网站中具备的反爬机制,从而可以获取 户网站中相关的数据。
robots.txt协议:君子协议。规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取。
比如知乎的爬虫robots其实下面还有长长一大串,几乎禁止了各种爬虫,但是每天还有数不尽的爬虫去爬知乎。
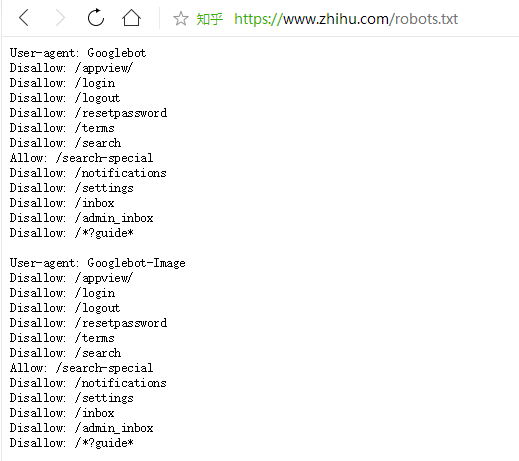
添加图片注释,不超过 140 字(可选)
推荐使用的版本:
- python 3.8 ,3.7也可以,但是最好不要用3.10等。
- pycharm
- 如果有基础或者玩⼉的⽐较6的玩家也可以选择以下⼯具:
- anaconda, jupyter
- Visual Studio Code
- python, IDLE (不推荐)
接下来就是安装了, Python安装过程就不赘述了. 注意安装的时候需要把python添加到环境变量中. 其他的没啥注意的,⾄于Pycharm的安装, 全程⼀路确定即可。
5.第⼀个爬⾍
⾸先,我们还是需要回顾⼀下爬⾍的概念。爬⾍就是我们通过我们写的程序去抓取互联⽹上的数据资源。⽐如, 此时我需要百度的资源。在不考虑爬⾍的情况下, 我们肯定是打开浏览器, 然后输⼊百度的⽹址,紧接着, 我们就能在浏览器上看到百度的内容了。那换成爬⾍呢? 其实道理是⼀样的。只不过, 我们需要⽤代码来模拟⼀个浏览器, 然后同样的输⼊百度的⽹址。那么我们的程序应该也能拿到百度的内容。对吧~
1 | from urllib.request import urlopen |
是不是很简单呢?
我们可以把抓取到的html内容全部写⼊到⽂件中, 然后和原版的百度进⾏对⽐,看看是否⼀致
1 | from urllib.request import urlopen |
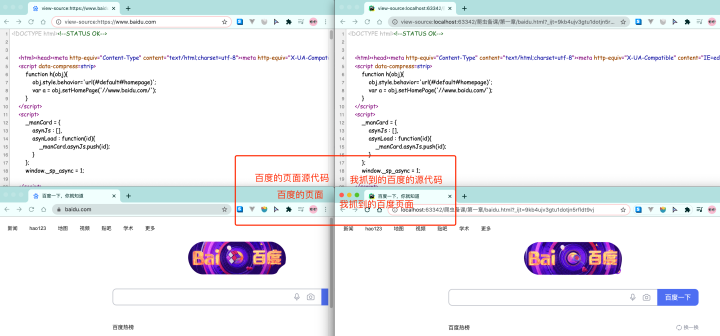
OK ~ 我们成功的从百度上爬取到了⼀个⻚⾯的源代码. 就是这么简单, 就是这么炫酷。







